Golang 培训 (1)¶
cy@maetimes¶
原则¶
基本语法细节需要自己读文档
帮助进入工作的内容
提前读 https://tour.golang.org/, 读effective go
基本特点¶
原生
编译
静态类型
单可执行文件
较全的标准库
gc
runtime级并发支持
较好的profile/microbenchmark机制
代码组织¶
跳过GOPATH, 我们项目中使用的module开始。
tmpcode $ mkdir gotutor && cd gotutor && go mod init gotutor
go: creating new go.mod: module gotutor
gotutor $ ls
go.mod
gotutor $ cat go.mod
module gotutor
go 1.13
做了什么¶
建立了目录gotutor
创建了module,名为gotutor
在目录下自动生成了go.mod文件
go.mod文件就是我们项目的配置文件, 第一行module gotutor就是包名, 我们这个项目中所有的包路径都会以gotutor开始,以文件系统目录来组织。
参考: https://blog.golang.org/using-go-modules
P0: Hello¶
创建文件main.go, 实现以下代码:
package main
func main() {
println("Hello, 中文")
}
执行¶
$ go run gotutor
Hello, 中文
$ go build gotutor
$ ./gotutor
Hello, 中文
$ ll
-rwxr-xr-x 1 cy cy 1.1M Nov 7 20:11 gotutor
做了什么¶
package main 指定文件所在包名, 同级目录的文件, 包名需要一致。
我们把包名为package main的包称为cmd, 其他的为pkg. cmd可以被编译成可执行文件。
./gotutor文件只打印hello, 它的二进制就有1.1M大小。go会把runtime打包进二进制文件中, 这里主要是它的大小。
组织代码¶
现有结构
$ tree
.
├── go.mod
└── main.go
0 directories, 2 files
调整后¶
$ tree
.
├── cmd
│ └── hello
│ └── main.go
└── go.mod
2 directories, 2 files
编译运行
$ go build gotutor/cmd/hello
$ ./hello
Hello, 中文
添加依赖¶
$ go get github.com/guptarohit/asciigraph
会在go.mod文件中添加如下内容
require github.com/guptarohit/asciigraph v0.5.1 // indirect
一般情况下,除非需要显示指定依赖版本, 或者替换版本地址. 我们不用手动修改go.mod文件, 也不要提交这个文件本地的修改.
编译时会自动拉取对应的版本代码.
使用新的依赖¶
修改hello/main.go程序如下:
import "github.com/guptarohit/asciigraph"
..
data := []float64{3, 4, 9, 6, 2, 4, 5, 8, 5, 10, 2, 7, 2, 5, 6}
graph := asciigraph.Plot(data)
fmt.Println(graph)
10.00 ┤ ╭╮
9.00 ┤ ╭╮ ││
8.00 ┤ ││ ╭╮││
7.00 ┤ ││ ││││╭╮
6.00 ┤ │╰╮ ││││││ ╭
5.00 ┤ │ │ ╭╯╰╯│││╭╯
4.00 ┤╭╯ │╭╯ ││││
3.00 ┼╯ ││ ││││
2.00 ┤ ╰╯ ╰╯╰╯
Makefile¶
一个module里可以有多个cmd项目, 我们利用Makefile管理编译命令.
GOCMD=go
GOBUILD=${GOCMD} build
GOCLEAN=${GOCMD} clean
.PHONY: hello
hello:
$(GOBUILD) gotutor/cmd/hello
类型,零值¶
基本类型
0
0.0
“”
结构体
指针
nil
数组
空数组
内置容器(slice, map)
nil
打印零值¶
func main() {
var i int
var s string
var f float64
var m map[string]interface{}
var xs []string
var arr [3]int
fmt.Println(i) // 0
fmt.Println(s) // ""
fmt.Println(f) // 0
fmt.Println(m == nil) // true
fmt.Println(xs == nil) // true
fmt.Println(arr) // [0,0,0]
}
零值JSON¶
零值JSON序列化(注意和客户端的交互)
var i int
var s string
var f float64
var m map[string]interface{}
var xs []string
var arr [3]int
bs, _ := json.Marshal(map[string]interface{}{
"i": i, "s": s, "f": f, "m": m, "xs": xs, "arr": arr,
})
fmt.Println(string(bs))
{
"arr": [ 0, 0, 0 ],
"f": 0, "i": 0, "s": "",
"m": null,
"xs": null
}
字符串¶
utf-8编码. 字符串与字节数组互转.
bs = []byte("瓦达西瓦")
s = string(bs)
fmt.Println(bs, s)
// [231 147 166 232 190 190 232 165 191 231 147 166] 瓦达西瓦
for _, r := range s {
fmt.Printf("%c", r)
fmt.Print(",")
}
fmt.Println(len(s), len(bs))
// 瓦,达,西,瓦,12 12
注意字符串的len返回的是实际存储的字节数, 而非字符(rune)数。
go中用术语rune(alias of int32)表示其他语言中的code point, 本质一样。
参考: https://blog.golang.org/strings
P2: MSetWeb¶
实现一个绘制manderbrot集的http服务器.
在gotutor/cmd下新建目录msetweb, 并新建文件main.go
在Makefile中添加新target.
msetweb:
$(GOBUILD) gotutor/cmd/msetweb
第一个http服务器¶
package main
import (
"log"
"net/http"
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("it works"))
})
log.Fatal(http.ListenAndServe(":8080", nil))
}
运行
$ go build gotutor/cmd/msetweb
$ ./msetweb
做了什么¶
导入库
import建立http路由
侦听请求
import¶
import (
"log"
"net/http"
)
导入了标准库中的日志和http库, go的导入都是源码导入, 依赖较快的编译器速度维护项目.
http路由¶
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("it works"))
})
建立/路径的处理逻辑, 是一个类型为func(w http.ResponseWriter, r *http.Request)的函数.
标准库遍历所有路由,找最长匹配,有优化的空间,相比io,成本很低,够用.
匿名函数¶
go中函数是一类对象(first-class), 可以作为值, 被传递, 被返回.
这里func(w ResponseWriter, r *http.Request)函数,作为HandleFunc的参数, 与/进行了绑定.
这里
ResponseWriter是interface向外输出的能力
Request是struct的一个指针需要处理的数据
interface¶
type ResponseWriter interface {
Header() Header
Write([]byte) (int, error)
WriteHeader(statusCode int)
}
鸭子类型, 只要实现了接口定义的函数, 不用显式的implements了这个接口, 就可以作为这种类型的值被传递.
interface{}¶
empty interface, 所有类型都实现了它, 所以能表达所有其他的类型, 一定程度的动态性, 不能滥用.
type assertion¶
一种常用的写法
var s interface{} = "foo"
if v, ok := s.(string); ok {
// do something
}
struct¶
struct tag¶
类似于java的注解, 一种加载字段上的元信息, 可以使用reflect库, 在读到的Field上通过Tag字段访问,实现特定的功能.
embedded struct¶
// TODO
reflect¶
编译器生成
_typ信息内存分配时在指针的bitmap上记录类型标识.
对象本身内存中不包含类型信息, 只有字段数据+对齐填充
reflect时转成interface操作Type & Value
值与指针¶
go中除了特殊容器和接口, 其他都是值语义
赋值就是拷贝
指针就是指向一个对象的内存地址
&取地址*deref没有指针操作
注意如果需要修改一个结构体, 或者method修改receiver的字段, 要用指针.
词法闭包¶
一个自身的作用域中出现了未自定/绑定的自由变量, 向上查找引用了外部量的函数值, 就是闭包.
const n = 5
var fs [n]func()
for i := 0; i < n; i++ {
fs[i] = func() {
fmt.Println(i)
}
}
for i := 0; i < n; i++ {
fs[i]()
}
词法闭包¶
上述代码中fs中存储是的就是闭包, 它们本地作用域中没有变量i, 向上查找, 引用了外层作用域中的i.
注意, 这段代码包含一种十分容易写出的错误.
由于实际是外部变量(名字)的引用, 因此循环体中的fs[i] = ..赋值, 实际最后打印了相同的i值5, 而非设想的从0到4.
正确的方式是:
for i := 0; i < n; i++ {
fs[i] = func(ii int) func() {
return func() { fmt.Println(ii) }
}(i)
}
绘制manderbrot集¶
一个复数集, 由于数据集很容易被划分, 经常作为并行计算的示例.
const (
MaxIter, W, H = 255, 800, 600
Wa, Wb, Ha, Hb = -2.0, 1.0, -1.5, 1.5
)
var (
EscapeColor = color.RGBA{0, 0, 0, 0}
)
func drawMSet() image.Image {
img := image.NewRGBA(image.Rect(0, 0, W, H))
for i := 0; i < W; i++ {
for j := 0; j < H; j++ {
c := complex(
Wa+float64(i)*(Wb-Wa)/(W-1),
Ha+float64(j)*(Hb-Ha)/(H-1),
)
z := c
var isset bool
for k := 0; k < MaxIter-1; k++ {
if cmplx.Abs(z) > 2 {
img.Set(i, j, color.RGBA{uint8(k % 4 * 64), uint8(k % 8 * 32), uint8(k % 16 * 16), 255})
isset = true
break
} else {
z = cmplx.Pow(z, 2) + c
}
}
if !isset {
img.Set(i, j, EscapeColor)
}
}
}
return img
}
运行¶
在/中, 响应画图请求, 生成图像, 使用png编码器, 通过w输出出去.
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "image/png")
img := drawMSet()
err := png.Encode(w, img)
if err != nil {
log.Println(err)
}
})
$ go run gotutor/cmd/msetweb
$ ./msetweb
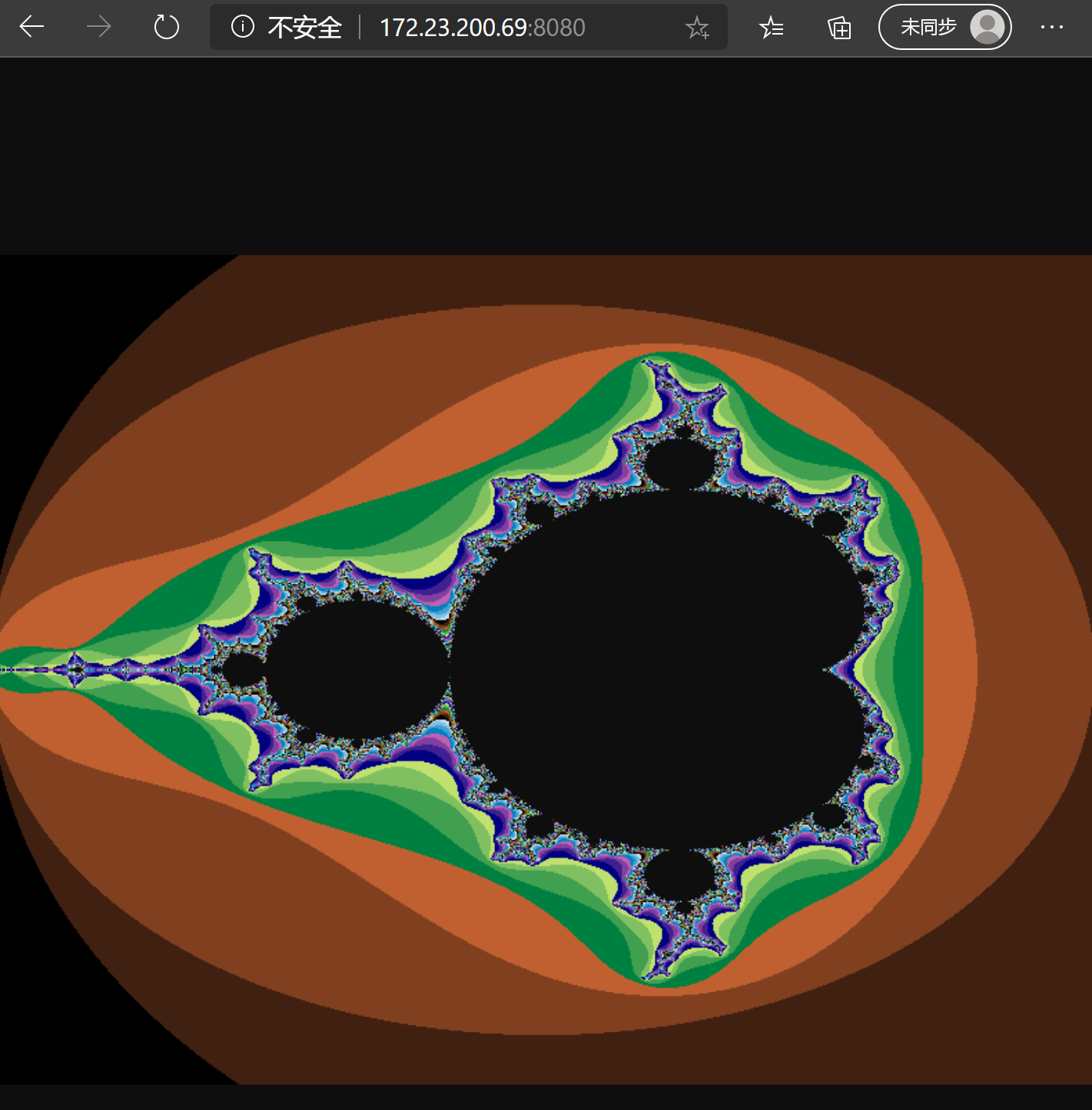
做了什么¶
const定义了长宽, 复数区间.
var定义了模块变量EscapeColor.
drawMSet方法中通过为W*H大小的二维数组每一个点,计算对应的复数,根据一个递推公式, 计算符合条件需要的迭代次数, 用这个次数决定该点的颜色, 画在Image上.
怎样命名¶
常量,变量都使用驼峰命名
作用域越小, 命名应该越简练
w,rfor i := 0; i < N; i++ {}不要写成
for index := 0; index < N; index++ {}
一眼能看出含义的不要文过饰非,做过多无用修饰
隐含上下文 + 名称能够完整准确表达含义即可
一些含义广泛的词, 即使有上下文, 也应该准确的限制住.
util,get,manager,dal, …要考虑方便文本检索, 不借助静态分析工具的情况下, 也能较快的定位使用.
怎样命名¶
导出规则
go的导出规则依赖命名规则, 没有其他关键字帮助处理.
首字母大写的符号, 在模块外可见.
Acronyms should be all capitals, as in ServeHTTP and IDProcessor.
HTTP而非HttpAPI而非ApiDAL而非DalID而非Id
参考: https://talks.golang.org/2014/names.slide#1
类型别名¶
type TypeA TypeB
对已有的类型加方法.
type T0 struct {
A int `json:"a"`
B int `json:"b`
}
type CompactT0 T0
func (t CompactT0) MarshalJSON() ([]byte, error) {
return json.Marshal(map[string]interface{}{"a": t.A})
}
类型别名¶
为CompactT0重新实现了标准库json中的Marshal接口.
type Marshaler interface {
MarshalJSON() ([]byte, error)
}
t0 := T0{A: 1, B: 2}
bs, _ = json.Marshal(t0)
ct0 := CompactT0(t0)
bs, _ = json.Marshal(ct0)
// print
运行
t0 {"a":1,"B":2}
ct0 {"a":1}
计算运行时间¶
drawMSet方法较慢, 打日志记录它的每次计算时间.
func drawMSet() image.Image {
t0 := time.Now()
defer func() {
elapsed := time.Now().Sub(t0)
log.Println("elapsed", elapsed)
}()
// ...
}
执行日志:
(base) ➜ gotutor go run gotutor/cmd/msetweb
2020/11/10 21:37:15 elapsed 2.0772316s
2020/11/10 21:37:17 elapsed 2.0719565s
defer¶
函数结束时执行一定代码.
returnval = xxx
call_defer
return
注意多个defer函数以LastInFirstOut的顺序执行.
panic & recover¶
panic()流程: 停止当前函数执行, 调用当前函数
defer函数, 向同一goroutine的上一级caller传递panic,直到panic在本goroutine未被recover, crash整个程序.一个goroutine中的panic如果没有被recover,会直接退掉整个程序. goroutineA中fork出一个新的goroutineB, 其中有panic, 不会被A的recover程序抓住.
https://blog.golang.org/defer-panic-and-recover
recover并打印stacktrace.
func () {
defer func() {
if err, ok := recover(); ok {
log.Println(string(debug.Stack())) // 线上要限制读栈的内存大小
}
}()
panic()
}
http middleware¶
请求到实际业务逻辑中间的处理层, 日志, 鉴权, recover等.
标准库对上面的handler函数定义了一个类型HandlerFunc.
type HandlerFunc func(ResponseWriter, *Request)
middleware本质是一个高阶函数, 输入一个HandlerFunc, 返回一个HandlerFunc(闭包).
// pkkr/util/hxxp/middleware.go
func RecoverJSONMiddleware(fn http.HandlerFunc) http.HandlerFunc
一个计算运行时间的middleware¶
func timingMiddleware(fn http.HandlerFunc) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
t0 := time.Now()
defer func() {
elapsed := time.Now().Sub(t0)
log.Println("elapsed", elapsed)
}()
fn(w, r)
}
}
http.HandleFunc("/", timingMiddleware(func(w http.ResponseWriter, r *http.Request) {})
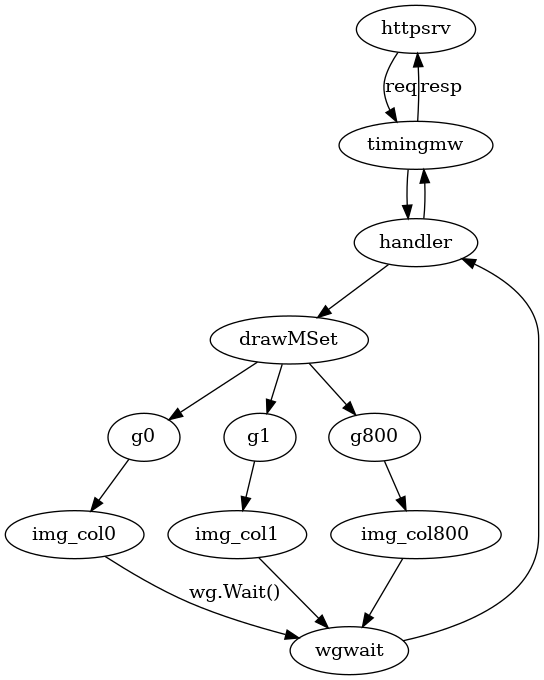
并行计算¶
前面绘图的接口响应需要2s多, 希望加速这个程序的计算. 分析程序的结构, 列与列数据的计算之间没有关联, 很容易按列切分, 分块计算.
wg := sync.WaitGroup{}
for i := 0; i < W; i++ {
wg.Add(1)
go func(i int) {
defer wg.Done()
for j := 0; j < H; j++ {
...
}
}(i)
}
wg.Wait()
运行效果¶
(base) ➜ gotutor ./msetweb
2020/11/11 20:02:06 elapsed 374.7928ms
2020/11/11 20:02:07 elapsed 383.1474ms
运行效果¶
开了800个goroutine并发计算, 最后得到5倍左右的加速. 什么是并发, 什么是并行?
Concurrency is not Parallelism https://talks.golang.org/2012/waza.slide
Concurrency vs. parallelism Concurrency is about dealing with lots of things at once.
Parallelism is about doing lots of things at once.
Not the same, but related.
Concurrency is about structure, parallelism is about execution.
Concurrency provides a way to structure a solution to solve a problem that may (but not necessarily) be parallelizable.
做了什么¶
go func() {}sync.WaitGroupwg.Add()wg.Done()wg.Wait()
goroutine¶
轻量
内存成本低
初始栈2k(没有linux的8mb限制)
调度成本低
用户态调度
无内核态切换
调度
1.14 后完全抢占式调度
G(oroutine)M(achine)P(rocessor)
参考: 调度器设计文档
参考: 详细分析
参考: 完全抢占式调度器proposal
并发容易出问题的地方¶
编译器优化
cpu执行优化
编译期, 运行期都会因优化, 改变程序本身的顺序.
内存模型规定了重排序优化的限制, 位于同步边界前后的语句存在happens-before关系, 不能被重排序.
编码中, 我们需要使用标准库提供的同步工具, 保证程序执行的顺序符合预期.
内存模型 https://golang.org/ref/mem
内存模型/同步边界¶
有同步边界的地方,会规定一种代码前后的happens-before顺序, 要求编译器/cpu优化不能跨过这样的顺序.
例如goroutine creation就是一个边界.
The go statement that starts a new goroutine happens before the goroutine’s execution begins.
这是我们在代码中发起并发查询能工作的前提.
var mvs []*MV
var users []*User
go func() { mvs = mvdal.GetMVs(mvids) }
go func() { users = userdal.GetUsers(userids) }
wg.Wait()
共享¶
goroutine间数据共享有两种方式
csp
goroutine-channel-goroutine
send/recv
shared memory
lock/unlock, read/write
Do not communicate by sharing memory; instead, share memory by communicating.
虽然建议这么做, 但是一般还是根据使用场景来定, 一些场景使用sync来同步goroutine可能更合理方便.
https://blog.golang.org/codelab-share
https://golang.org/doc/effective_go.html
channel¶
unbuffered
可想想象成一个锁
lock
<-ch
unlock
ch <- val
从channel中读数据会阻塞
向有值的channel中写数据也会阻塞
buffered
想象成一个容量为cap(xx)的queue
向容量已满的channel中写会阻塞
从空channel中读会阻塞
channel¶
closed
close已经关闭的channel会panic向已经关闭的channel发送数据会panic
TODO 使用buffered-channel实现semaphore.
select/multiplexing¶
select阻塞当前执行流, 等待case条件中有任一信号进入, 执行case条件,然后向下执行.
注意select接受到一个信号进入处理逻辑后,本次执行不再侦听其他case分支消息.
通常和for组合侦听处理多路消息.
for {
select {
case <-ch0:
// dosth
case <-ch1:
// dosth
}
}
context¶
cancellation
需要全链路都要支持取消
timeout
value
注意逐层包装后的context等同于一个链表
方法签名设计时第一个参数为(ctx context.Context)
有争议的一套机制, 支持和反对文章都很多
context¶
使用context控制一个对下游的访问超时.
func call(ctx context.Context, duration time.Duration, f func()) error {
ctx, cancel := context.WithTimeout(ctx, duration)
defer cancel()
sig := make(chan struct{})
go func() {
defer func() {
sig <- struct{}{}
}()
f()
}()
select {
case <-sig:
case <-ctx.Done():
return ctx.Err()
}
return nil
}
context 接上¶
这个函数假设下游函数f对没有对context的进行处理. 那么下面调用会发生什么情况.
call(context.Backgroup(), 1*time.Second, func() {
for i := 0; i < 10; i++ {
log.Println(i)
time.Sleep(1*time.Second)
}
})
call调用在1秒时发生了超时,中断了执行返回error. 但是被真实被调用函数不受这个影响, 仍然继续执行下去.
sync¶
sync.Mutex注意go中的mutex不支持重入(reentrant, recursive lock)
一个典型的场景, 同一个reciever, 在调用一个获取锁的方法后,再次调用它, 会死锁.
sync.RWLocksync.WaitGroupwg.Add增加待等待计数
wg.Done减少待等待计数
wg.Wait阻塞, 直至计数为0
sync.Map¶
map容器并发可以并发读, 不能有并发读写. 检测到即fatal, 程序退出.
sync.Map是个值, 不能通过赋值传参等形式拷贝传递结构体本身, 使用指针. 否则出现异常的情况.
https://github.com/gophercon/2017-talks/blob/master/lightningtalks/BryanCMills-AnOverviewOfSyncMap/An%20Overview%20of%20sync.Map.pdf
data race detector¶
检测多个goroutine访问同一段未被同步的内存
go build -race ...
需要实际运行才能进行检测, 触发后会写以下信息到指定输出上(stderr)
==================
WARNING: DATA RACE
Write at 0x00c0002d0af3 by goroutine 171:
main.(*Lounge).Stop()
/opt/zeus/pkkr/cmd/loungesvc/lounge.go:260 +0x99
main.main.func1()
/opt/zeus/pkkr/cmd/loungesvc/main.go:207 +0x14d
Previous read at 0x00c0002d0af3 by goroutine 201:
main.(*Lounge).LogLoop()
/opt/zeus/pkkr/cmd/loungesvc/lounge.go:239 +0xb3
Goroutine 171 (running) created at:
main.main()
/opt/zeus/pkkr/cmd/loungesvc/main.go:203 +0x25fd
Goroutine 201 (running) created at:
main.(*Lounge).Start()
/opt/zeus/pkkr/cmd/loungesvc/lounge.go:253 +0xe6
main.main()
/opt/zeus/pkkr/cmd/loungesvc/main.go:219 +0x2756
==================
Found 6 data race(s)
go test¶
标准库自带一套比较好用的测试工具
单元测试
复杂的计算逻辑要充分测试
拿不准的代码一定要测, 不能拿到线上去”冒”
micro-benchmark
高频调用的代码, 进行性能测试
go test test¶
例如我们实现了一个字符串数组去重的函数, 测试它的逻辑是否正常.
func TestDedupStrs(t *testing.T) {
xs := []string{"a", "b", "a", "c", "d", "e", "b"}
uxs := DedupStrs(xs)
if len(uxs) != 5 {
t.Errorf("len(uxs) should be 5, but get %d", len(uxs))
}
}
$ go test pkkr/util/collection
(base) ➜ pkkr git:(master) ✗ go test pkkr/util/collection -v
=== RUN TestDedupStrs
--- PASS: TestDedupStrs (0.00s)
PASS
ok pkkr/util/collection 0.003s
go test bench¶
func BenchmarkDedupStrs(b *testing.B) {
b.ReportAllocs()
xs := []string{"a", "b", "a", "c", "d", "e", "b"}
for i := 0; i < b.N; i++ {
DedupStrs(xs)
}
}
这里b.ReportAllocs()是报告它的内存使用.
$ go test -bench=. pkkr/util/collection -v
BenchmarkDedupStrs-8 6086265 197 ns/op 112 B/op 1 allocs/op
...
会报告运行次数, 平均耗时, 内存大小, 内存分配次数等.
怎样写代码(next?)¶
简单几条
data-driven
面向数据编程, 围绕数据组织程序.
不过度设计, 抽象直接单一, 层层封装要少, 不为了模式而模式, 一般不要套模式.
保持简单, 直接
简单可理解, 不对程序正确运行条件做隐含假设
利用组合
没有继承,没有oo,不要强行oo
分离计算和副作用(side-effect)
可测性