6.824¶
Introduction¶
@20190819
容错
需求
高可用
duration
方式
复制服务器
一致性
困哪
“replica” servers are hard to keep identical
clients may crash midway through multi-step update
servers crash at awkward moments
network may take live servers look dead; risk of “split brain”.
一致性与性能的矛盾
consistency requires communication, e.g. to get latest Put(). “Strong consistency” often leads to slow systems.
High performance often imposes “weak consistency” on applications.
https://pdos.csail.mit.edu/6.824/papers/mapreduce.pdf
Map-Reduce¶
编程模型
map(k1, v1) -> list(k2, v2)
reduce(k2, list(v2)) -> list(k2, v3)
Word-Count示例
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
例程
Distributed Grep
Count of URL Access Frequency
Reverse Web-Link Graph
Term-Vector per Host
Inverted Index
Distributed Sort
实现
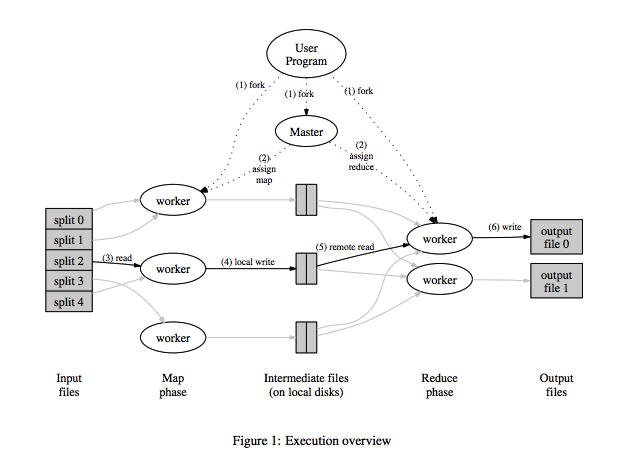
input file split分片大小
16mb ~ 64mb
master调度worker进行map和reduce, 谁空闲分配给谁.
map worker读输入分片, 结果周期存入本地盘, 将位置报告给master, master通知reduce去拿(rpc读, p2p)
reduce先排序读入的数据, 按顺序发给用户自定义Reduce函数.
reduce的结果append到一个最终文件(partition)
容错
worker失败
master定时ping worker, 判定worker是否失败
失败后丢弃计算结果重新找worker计算指定数据
master失败
定期将master内存镜像到checkpoint.
失败后,拷贝最近checkpoint,新启动master.
checkpoint后的任务被重放
局部性
网络带宽是稀缺资源
数据, map任务, reduce任务就近分配
gfs的case是64mb数据块就近
任务粒度
M个map任务,R个reduce任务,原则上, M,R要远大于worker机器数量,便于任务调度. 但是任务数据也有限制, 上下限内的合理值.
master做O(M+R)调度, 在内存中维持O(M*R)个状态.
straggler问题:
一台工作机在少量任务上工作耗时超长.
任务备份来解决straggler问题, 一个mapreduce任务快结束时, master将仍在运行的任务做一个副本任务重新执行, 其中有一执行完毕,就标识任务结束.